Microbenchmarks#
When we first received our iPad Pro (11”, Wi-Fi, 1 TB), we knew very little about M4 other than Apple’s specifications. There were rumors that M4 supports SME(2) and perhaps SVE(2), but details were lacking. This section describes a series of microbenchmarks we ran to explore the capabilities of M4.
Note
Our microbenchmarks were chosen to guide our implementation of matrix-matrix multiplication kernels. Other workloads may require additional benchmarks not covered here.
SVE and SME Support#
Our first two benchmarks are simple.
We want to see if M4 supports SVE and SME.
To do this, we run a few instructions and see if the iOS app crashes on us.
In the case of SVE, we set one of the predicate registers and issue an fmla instruction:
.text
.global _sve_support
.align 4
_sve_support:
ptrue p0.b
fmla z0.s, p0/m, z30.s, z31.s
ret
Unfortunately, it turns out that we got off to a bad start.
Running SVE instructions outside of streaming is a bad idea on M4 and results in an EXC_BAD_INSTRUCTION:
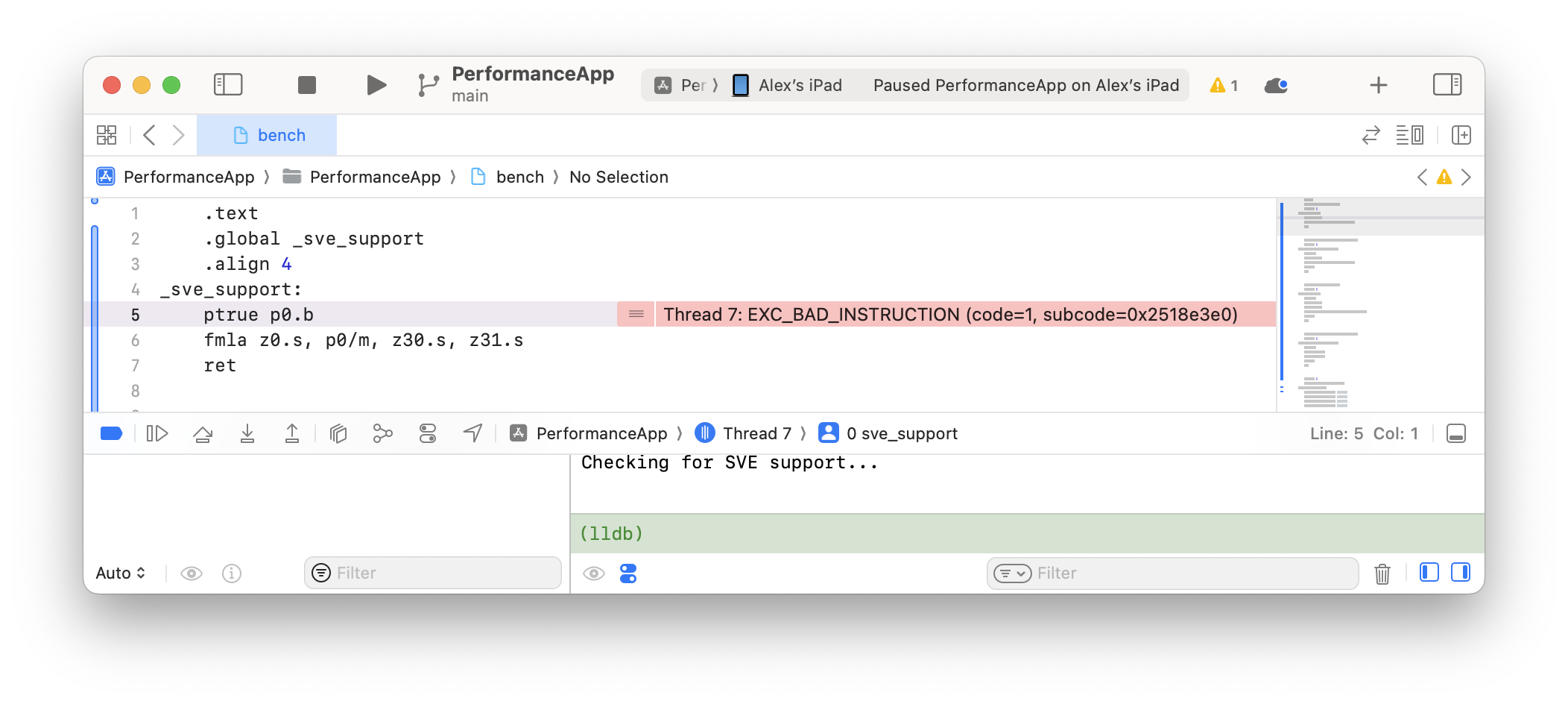
Fig. 6 Xcode screenshot of the error message when running non-streaming SVE instructions on M4.#
Next, let’s see if we can at least run SVE instructions in streaming mode:
.global _sve_streaming_support
.align 4
_sve_streaming_support:
smstart
ptrue p0.b
fmla z0.s, p0/m, z30.s, z31.s
smstop
ret
This code runs fine, great! Let us move on to SME, the extension we are most interested in:
.global _sme_support
.align 4
_sme_support:
smstart
ptrue p0.b
ptrue p1.b
fmopa za0.s, p0/m, p1/m, z0.s, z1.s
smstop
ret
Again, the code runs perfectly. It is time to do some more advanced benchmark work.
Vector Length#
The next obvious question to ask is the size of the vector registers when executing streaming SVE and SME code. Our microbenchmark for determining the vector length is super simple:
.global _sve_streaming_vlength
.align 4
_sve_streaming_vlength:
smstart
ldr z0, [x0]
str z0, [x1]
smstop
ret
We simply fill the vector register z0 with the values starting at the first pointer (x0).
Then the values in z0 are written back to memory at location x1.
Effectively, we can simply count how many values made it back to memory and infer the vector length.
Our corresponding boilerplate C code is as follows:
printf( "Determining vector length of SVE in streaming mode \n" );
float l_a[32];
float l_b[32] = {0};
for( int64_t l_i = 0; l_i < 32; l_i++ ){
l_a[l_i] = (float) l_i + 1;
}
sve_streaming_vlength( l_a, l_b );
int64_t l_num_bits = 0;
for( int64_t l_i = 0; l_i < 32; l_i++ ){
if( l_b[l_i] > 0 ){
l_num_bits += 32;
}
}
printf( " %lld bits\n", l_num_bits );
Running this gives us a vector length of 512 bits.
Peak Performance#
Now that we have a rough idea of what kind of floating-point instructions we can run on M4, we want to study what kind of performance they can deliver in the best case. We benchmark the best case by hot-looping over vector instructions in the case of Neon and streaming SVE, and over outer-product instructions in the case of AMX and SME. The benchmarks are written to avoid possible inter-instruction dependencies. For now, we limit our considerations to FP32 arithmetic.
Since the code is a bit long, we only refer to our GitHub repository. In summary, the single-core FP32 performance of the M4 cores is as follows (2d9566d):
Core Type |
Instruction |
FP32 GFLOPS |
|---|---|---|
P |
FMLA (Neon) |
107 |
P |
FMLA (SSVE) |
31 |
P |
FMLA (SME2) |
502 |
P |
AMX FMA |
2006 |
P |
SME FMOPA |
2008 |
E |
FMLA (Neon) |
46 |
E |
FMLA (SSVE) |
22 |
E |
FMLA (SME2) |
179 |
E |
AMX FMA |
357 |
E |
SME FMOPA |
357 |
Data Types#
SME supports a number of different datatypes when executing outer products. The corresponding instructions typically exist in two flavors. First, an instruction can use the same data type for both input and output. These instructions are called non-widening. One such example is the FP32 FMOPA (non-widening) instruction that we just benchmarked. Second, the output datatype of an instruction can have more bits than the input data type. These instructions are called widening. An example of a widening instruction is BFMOPA (widening). For 512-bit SME, the BFMOPA (widening) instruction computes a matrix-matrix multiplication with M=N=16 and K=2. The input matrices are in BF16 while the accumulation is in FP32. As a result, BFMOPA (widening) performs twice as many floating-point operations as the non-widening FP32 FMOPA.
Microbenchmarking different data types, we measured the following performance (2d9566d):
Instruction |
Input Dtype |
Output Dtype |
P-Core GOPS |
E-Core GOPS |
|---|---|---|---|---|
SMOPA |
I8 |
I32 |
4020 |
716 |
SMOPA |
I16 |
I32 |
2010 |
358 |
FMOPA |
FP16 |
FP32 |
2010 |
358 |
BFMOPA |
BF16 |
FP32 |
2011 |
357 |
FMOPA |
FP64 |
FP64 |
503 |
89 |
We see that the performance of instructions with reduced precision is underwhelming. Effectively the instruction throughput is halved for the widening instructions, which offsets the gains from the dot products performed. Using 8-bit integers as inputs and accumulating to 32-bit integers results in a moderate 2x speedup. FP64 FMOPA is four times slower than FP32 FMOPA, which is consistent with AMX results on earlier Apple silicon.
Tile Reuse#
The FP32 SME FMOPA instruction computes the outer product of two scalable vector registers and adds the result to one of four ZA tiles. The names of the four ZA tiles are ZA0, ZA1, ZA2, and ZA3. One of the tiles holds 16x16=256 values for M4’s 512-bit SME implementation. Since we are accumulating in the ZA tiles, there is a read-after-write dependency between two consecutive instructions writing to the same ZA tile. When writing microkernels, we need to be aware of these dependencies, as they can affect performance.
We microbenchmark the behavior of M4 by hot-looping over blocks with increasing reuse distances. Initially, we simply accumulate in a single ZA tile:
fmopa za0.s, p0/m, p1/m, z0.s, z1.s
fmopa za0.s, p0/m, p1/m, z2.s, z3.s
fmopa za0.s, p0/m, p1/m, z4.s, z5.s
fmopa za0.s, p0/m, p1/m, z6.s, z7.s
Next, we use two tiles to accumulate:
fmopa za0.s, p0/m, p1/m, z0.s, z1.s
fmopa za1.s, p0/m, p1/m, z2.s, z3.s
fmopa za0.s, p0/m, p1/m, z4.s, z5.s
fmopa za1.s, p0/m, p1/m, z6.s, z7.s
Finally, we use all available tiles, which is consistent with the setting used to determine the SME peak:
fmopa za0.s, p0/m, p1/m, z0.s, z1.s
fmopa za1.s, p0/m, p1/m, z2.s, z3.s
fmopa za2.s, p0/m, p1/m, z4.s, z5.s
fmopa za3.s, p0/m, p1/m, z6.s, z7.s
Running these settings on a performance core and an efficiency core, we obtained the following results (2d9566d):
Core Type |
#Tiles |
FP32 GFLOPS |
|---|---|---|
P |
1 |
503 |
P |
2 |
1005 |
P |
4 |
2008 |
E |
1 |
357 |
E |
2 |
357 |
E |
4 |
357 |
This tells us that we need to use all available ZA tiles on the performance cores for FP32 FMOPA kernels. Interestingly, this is not an issue on the efficiency cores.
SME Pstate#
If we want to use SME, we must be in the SME architectural state. As a callee it is initially not clear whether the caller has set the SME architectural state. In such a case we must use SMSTART to enable access to the SME architectural state. When writing a JITter in later stages, we have two options:
We burden the caller with setting the SME architectural state. In this case, we can stay in the SME state between kernel calls and avoid the possible overhead of SMSTART and SMSTOP.
Detect the SME architectural state and set it if necessary. This will fully expose the overhead of switching between states.
We benchmark the overhead by artificially inserting SMSTART and SMSTOP instructions into our FMOPA peak kernel. For example, we group 128 FMOPA instructions into one SMSTART-SMSTOP block using the following code snippet:
loop_peak_sme_fmopa_smstart_smstop_128_outer:
sub x0, x0, #1
smstart
mov x1, #4
loop_peak_sme_fmopa_smstart_smstop_128_inner:
sub x1, x1, #1
fmopa za0.s, p0/m, p1/m, z0.s, z1.s
fmopa za1.s, p0/m, p1/m, z2.s, z3.s
fmopa za2.s, p0/m, p1/m, z4.s, z5.s
fmopa za3.s, p0/m, p1/m, z6.s, z7.s
fmopa za0.s, p0/m, p1/m, z8.s, z9.s
fmopa za1.s, p0/m, p1/m, z10.s, z11.s
fmopa za2.s, p0/m, p1/m, z12.s, z13.s
fmopa za3.s, p0/m, p1/m, z14.s, z15.s
fmopa za0.s, p0/m, p1/m, z16.s, z17.s
fmopa za1.s, p0/m, p1/m, z18.s, z19.s
fmopa za2.s, p0/m, p1/m, z20.s, z21.s
fmopa za3.s, p0/m, p1/m, z22.s, z23.s
fmopa za0.s, p0/m, p1/m, z24.s, z25.s
fmopa za1.s, p0/m, p1/m, z26.s, z27.s
fmopa za2.s, p0/m, p1/m, z28.s, z29.s
fmopa za3.s, p0/m, p1/m, z30.s, z31.s
fmopa za0.s, p0/m, p1/m, z0.s, z1.s
fmopa za1.s, p0/m, p1/m, z2.s, z3.s
fmopa za2.s, p0/m, p1/m, z4.s, z5.s
fmopa za3.s, p0/m, p1/m, z6.s, z7.s
fmopa za0.s, p0/m, p1/m, z8.s, z9.s
fmopa za1.s, p0/m, p1/m, z10.s, z11.s
fmopa za2.s, p0/m, p1/m, z12.s, z13.s
fmopa za3.s, p0/m, p1/m, z14.s, z15.s
fmopa za0.s, p0/m, p1/m, z16.s, z17.s
fmopa za1.s, p0/m, p1/m, z18.s, z19.s
fmopa za2.s, p0/m, p1/m, z20.s, z21.s
fmopa za3.s, p0/m, p1/m, z22.s, z23.s
fmopa za0.s, p0/m, p1/m, z24.s, z25.s
fmopa za1.s, p0/m, p1/m, z26.s, z27.s
fmopa za2.s, p0/m, p1/m, z28.s, z29.s
fmopa za3.s, p0/m, p1/m, z30.s, z31.s
cbnz x1, loop_peak_sme_fmopa_smstart_smstop_128_inner
smstop
cbnz x0, loop_peak_sme_fmopa_smstart_smstop_128_outer
We measured performance for 8 to 128 FMOPA instructions in each SMSTART-SMSTOP block (2d9566d):
#FMOPA Instructions |
P-Core FP32 GFLOPS |
E-Core FP32 GFLOPS |
|---|---|---|
8 |
434 |
238 |
16 |
845 |
286 |
32 |
1606 |
318 |
64 |
1891 |
336 |
128 |
1947 |
347 |
We see that for small kernels, we may want to expose the SME architectural state to the caller. For larger kernels, we can detect the SME architectural state and set it in the kernel if necessary.
Multicore Performance#
We use Apple’s Dispatch framework to test our microbenchmarks on multiple cores. Dispatch allows us to spawn threads using dispatch_group_async and insert a barrier using dispatch_group_wait. Since our M4 has four performance cores and six efficiency cores, we used 1-10 threads. When running our FMLA (Neon) and FMOPA (SME) benchmarks, we measured the following performance (2d9566d):
Instruction |
#Threads |
User-Interactive FP32 GFLOPS |
Utility FP32 GFLOPS |
|---|---|---|---|
FMLA (Neon) |
1 |
107 |
46 |
FMLA (Neon) |
2 |
202 |
91 |
FMLA (Neon) |
3 |
297 |
133 |
FMLA (Neon) |
4 |
396 |
178 |
FMLA (Neon) |
5 |
443 |
221 |
FMLA (Neon) |
6 |
485 |
259 |
FMLA (Neon) |
7 |
529 |
258 |
FMLA (Neon) |
8 |
572 |
260 |
FMLA (Neon) |
9 |
607 |
259 |
FMLA (Neon) |
10 |
636 |
261 |
FMOPA (SME) |
1 |
2009 |
357 |
FMOPA (SME) |
2 |
1983 |
358 |
FMOPA (SME) |
3 |
1983 |
358 |
FMOPA (SME) |
4 |
1983 |
358 |
FMOPA (SME) |
5 |
2341 |
358 |
FMOPA (SME) |
6 |
2286 |
358 |
FMOPA (SME) |
7 |
2341 |
358 |
FMOPA (SME) |
8 |
2343 |
358 |
FMOPA (SME) |
9 |
2329 |
359 |
FMOPA (SME) |
10 |
2335 |
359 |
Looking at the FMLA (Neon) performance, we see that threads with the quality-of-service class QOS_CLASS_UTILITY are using only the efficiency cores.
This is consistent with the CPU utilization shown in Xcode which shows a maximum utilization of 600%, even when more than six threads are used.
The measured Neon scaling performance of QOS_CLASS_USER_INTERACTIVE threads is consistent with that of a heterogeneous CPU.
Initially, when 1-4 threads are used, the results suggest that they are running only on performance cores.
After that, each thread adds about 43.5 GFLOPS, which is roughly the performance of an efficiency core.
Therefore, 10 user-interactive threads are using all 10 cores, which is also indicated by the 1000% CPU utilization shown in Xcode in this case.
The scaling behavior of the FMOPA (SME) microbenchmark indicates that M4 has two SME units, one associated with the performance cores and one associated with the efficiency cores. Using utility threads, the performance is constant at 357-359 GFLOPS. Thus, a single thread is sufficient to fully utilize the SME unit associated with the efficiency cores.
The FMOPA (SME) results for the user-interactive threads show a more interesting behavior. Initially, when using 1-4 threads, the performance drops slightly from 2009 to 1983 GFLOPS. Using a fifth thread, we see a performance increase of 358 GFLOPS. Adding more threads does not increase throughput any further. We conclude that the four user-interactive threads use a single SME unit, while more threads also use the second unit. We ran some additional tests to test this theory. Specifically, we ran the microbenchmark with a single user-interactive thread and a single utility thread. In this case, we achieved a cumulative performance of 2371 GFLOPS.
Bandwidth: ZA Array#
At some point, every kernel has to load data into registers and write it back into memory after processing. We have several instructions for loading and storing data. In this section, we will study the performance of the following instructions:
Instruction |
Registers |
#Bytes |
Requirements |
|---|---|---|---|
1× Z |
64 |
FEAT_SVE or FEAT_SME |
|
1× Z |
64 |
FEAT_SVE or FEAT_SME |
|
1× Z |
64 |
FEAT_SVE or FEAT_SME |
|
1× Z |
64 |
FEAT_SVE or FEAT_SME |
|
2× Z |
128 |
FEAT_SME2 or FEAT_SVE2p1 |
|
2× Z |
128 |
FEAT_SME2 or FEAT_SVE2p1 |
|
4× Z |
256 |
FEAT_SME2 or FEAT_SVE2p1 |
|
4× Z |
256 |
FEAT_SME2 or FEAT_SVE2p1 |
|
2× Z |
128 |
FEAT_SME2 |
|
2× Z |
128 |
FEAT_SME2 |
|
4× Z |
256 |
FEAT_SME2 |
|
4× Z |
256 |
FEAT_SME2 |
|
1× ZA |
64 |
FEAT_SME |
|
1× ZA |
64 |
FEAT_SME |
Our read benchmarks repeatedly load the same data from memory into the ZA array. Conversely, the write benchmarks store from the ZA array to the same location in memory. We added additional Z-to-ZA or ZA-to-Z copies for configurations that use instructions that load or store to or from Z registers rather than directly to or from the ZA array.
The smallest configurations repeatedly load or store 2048 KiB (\(2^{11}\) bytes). The largest configurations load or store 2 GiB (\(2^{31}\) bytes). The 1 TB iPad Pro utilized for testing has 16 GB of memory, which would allow for larger settings. However, when we increased the memory footprint further, we got “BAD_ACCESS” errors when initializing the allocated arrays. This is an iOS limitation, as calling the os_proc_available_memory function showed about 5 GiB of available memory.
Where relevant, we set all predicate bits used in the loads or stores to perform full loads or stores. We also varied the alignment of the arrays’ base pointers from 16 to 128 bytes. Further, we added a 30-second cooldown before each run because we noticed that the iPad got warm when running the benchmark settings back-to-back. We ran the benchmarks on a single performance core and obtained the following results (2d9566d):

Fig. 7 LDR_Z performance on a single performance core.# |

Fig. 8 LD1W (scalar plus immediate, single register) performance on a single performance core.# |

Fig. 9 LD1W (scalar plus immediate, 2x consecutive registers) performance on a single performance core.# |

Fig. 10 LD1W (scalar plus immediate, 4x consecutive registers) performance on a single performance core.# |

Fig. 11 LD1W (scalar plus immediate, 2x strided registers) performance on a single performance core.# |

Fig. 12 LD1W (scalar plus immediate, 4x strided registers) performance on a single performance core.# |

Fig. 13 LDR (array vector) performance on a single performance core.# |
|

Fig. 14 STR_Z performance on a single performance core.# |

Fig. 15 ST1W (scalar plus immediate, single register) performance on a single performance core.# |

Fig. 16 ST1W (scalar plus immediate, 2x consecutive registers) performance on a single performance core.# |

Fig. 17 ST1W (scalar plus immediate, 4x consecutive registers) performance on a single performance core.# |

Fig. 18 ST1W (scalar plus immediate, 2x strided registers) performance on a single performance core.# |

Fig. 19 ST1W (scalar plus immediate, 4x strided registers) performance on a single performance core.# |

Fig. 20 STR (array vector) performance on a single performance core.# |
The graphs show some interesting details. First, the performance of all read settings tested drops sharply for a memory footprint above 8 MiB (\(2^{23}\) bytes). This suggests that the L2 size is in this range.
Second, the read bandwidth depends heavily on the instruction used. The highest bandwidth under 8 MiB of data is obtained with the microbenchmark that uses LD1W instructions that load into four Z registers (256 bytes per load). In this case, up to 925 GiB/s is possible. The LD1W variant that loads only a single Z register (64 bytes per load) achieves only 376 GiB/s. Loading directly into the ZA array using the LDR (array vector) instruction results in 375 GiB/s, which is much slower than the 128-byte and 256-byte indirect loads. Using different instructions to write data has little effect on bandwidth.
Third, depending on the instructions used, data alignment can have a large impact on performance. Most notable is an increase in bandwidth for 64-byte and 128-byte when using LDR (array vector) and 128-byte LD1W instructions. We also observe an improvement in write bandwidth by aligning to 64-byte boundaries when less than 8 KiB is transferred to memory.
With respect to a matrix kernel computing \(C \mathrel{+}= AB^T\) with MOPA instructions, we have different data location requirements. The data of the two input matrices \(A\) and \(B^T\) must be loaded into the Z registers, while the data of the output matrix \(C\) must be loaded into the ZA tiles. Since the performance of the LDR/STR (vector) setting has a low bandwidth, we may want to load the data of \(C\) into the Z registers first and then copy it to the ZA tiles. Conversely, after the computation, we should probably copy the data from the ZA tiles to the Z registers and then store it to memory. This procedure is also followed in lines 105-127 of the FP32 matmul example in the SME Programmer’s Guide.
Summary and Outlook#
We have benchmarked most of the properties of SME on M4 that we need to understand when writing a JITter for small GEMMs. Overall, the behavior of M4 when executing SME data processing instructions is quite similar to what we observed when microbenchmarking AMX on M1.