8. Collective Communication
Collective operations involve communication among a group of processes rather than just between pairs of processes. These operations are essential for parallel algorithms and can significantly improve the efficiency of parallel programs by allowing multiple processes to work together.
8.1. Common Operations
MPI_Bcast (Broadcast):
This operation sends a message from one process (the root) to all other processes in the communicator.
MPI_Bcast(void* buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm);
MPI_Scatter (Scatter):
This operation divides data on the root process and distributes the obtained chunks to the other processes in the communicator.
MPI_Scatter(void* sendbuf, int sendcount, MPI_Datatype sendtype, void* recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm);
MPI_Gather (Gather):
The inverse of MPI_Scatter, this operation collects data chunks from all processes and sends it to the root process.
MPI_Gather(void* sendbuf, int sendcount, MPI_Datatype sendtype, void* recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm);
MPI_Reduce (Reduce):
This operation performs a reduction operation (e.g., sum, product, maximum) on data ditributed across all processes. The result stored on a specified root process.
MPI_Reduce(void* sendbuf, void* recvbuf, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm);
MPI_Allreduce (Allreduce):
Similar to MPI_Reduce, but the result is broadcasted to all processes.
MPI_Allreduce(void* sendbuf, void* recvbuf, int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm);
MPI_Barrier (Barrier):
This operation synchronizes all processes in the communicator.
MPI_Barrier(MPI_Comm comm);
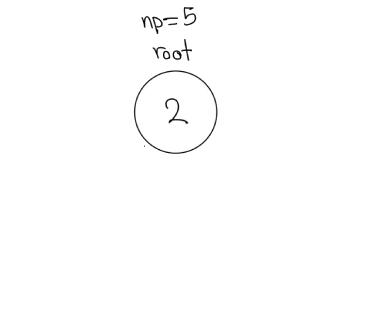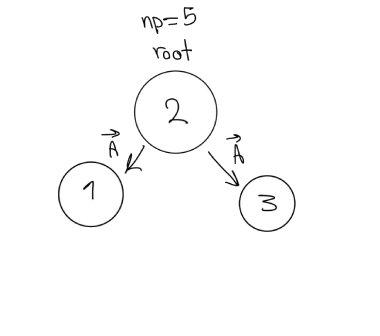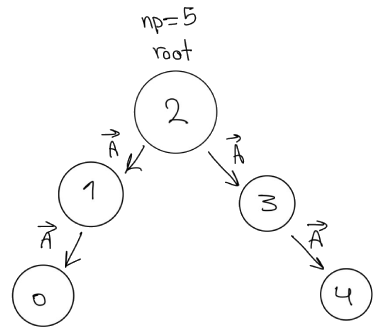
Fig 7.1.1 Broadcast with a tree approach.
Task
Write a C/C++ function named “my_broadcast” in which the root process broadcasts the values of an array of doubles to all other processes.
Initialize the array of double values with a user-defined size, N, specified through the Terminal.
Use only Point-to-Point communication. Your approach could look like a tree (Fig. 7.1.1).
Benchmark your “my_broadcast” function for N=100000 and 10 processes on the
shortorstandardpartition of the draco cluster. Compare the runtime with the standard “MPI_Bcast” function. Use the “MPI_Wtime()” function described in Section 6.3 for your measurements.Include the slurm script, the job output, the implementation itself and all necessary documentation in your submission.
- Bonus:
We compare the runtime of your implementation with the implementations of the other teams
The winner receives 2 extra points
submit an anonymous name for your team
8.2. Communicators
In all previous exercises, we have used the communicator MPI_COMM_WORLD. Often this is sufficient because we only communicate with one or all processes at a time. For more complex applications, we may need to communicate with only a few processes at a time. In this case we can create a new communicator.
MPI_Comm_split: Creates new communicators by “splitting” a communicator into a group of sub-communicators based on the input values color and key.
int MPI_Comm_split( MPI_Comm comm,
int color,
int key,
MPI_Comm *newcomm);
comm: The old communicator.color: Determines to which new communicator each process will belong. All processes that pass the same value forcolorare assigned to the same communicator.key: Determines the rank within each new communicator. The process that passes the smallest value forkeywill be rank 0.newcomm: The new communicator.
Task
Custom communicators
Create two communicators by splitting
MPI_COMM_WORLDwithMPI_Comm_Splitbased on odd and even ranks.Use the ranks of
MPI_COMM_WORLDaskeyfor your new communicators.Broadcast a random integer from rank 0 to all other ranks in the respective communicators.
Print the received data on each rank after the broadcast
Free your communicators with
MPI_Comm_free.